
几个月前,爱范儿在一台 M3 Ultra 的 Mac Studio 告捷部署了 671B 的 DeepSeek 的土产货大模子(4-bit 量化版)。比拟传统 GPU 决议需要复杂的内存束缚和数据交换,苹果 512GB 的长入内存不错径直将总共这个词模子加载到内存中,幸免了频频的数据搬运。
而要是把 4 台顶配 M3 Ultra 的 Mac Studio,通过开源器具串联成一个「桌面级 AI 集群」,是否就能把土产货推理的天花板再举高一个维度?
这恰是来自英国创业公司 Exo Labs 正在尝试治理的问题。
「不要认为牛津大学 GPU 多得用不完」
你可能会认为像牛津这么的顶级大学笃定 GPU 多得用不完,但其实完好意思不是这么。
Exo Labs 首创东说念主 Alex 和 Seth 毕业于牛津大学。即使在这么的顶尖高校作念询查,念念要使用 GPU 集群也需要提前数月列队,一次只可苦求一张卡,进程漫长而低效。
他们意志到,现时 AI 基础设施的高度聚合化,使得个东说念主询查者和微型团队被角落化。
旧年 7 月,他们启动了第一次实验,用两台 MacBook Pro 告捷串联跑通了 LLaMA 模子。诚然性能有限,每秒只可输出 3 个 token,但依然足以考证 Apple Silicon 架构用于 AI 分袂式推理的可行性。

委果的移动点来自 M3 Ultra Mac Studio 的发布。512GB 长入内存、819GB/s 的内存带宽、80 核 GPU,再加上 Thunderbolt 5 的 80Gbps 双向传输才能——这些规格让土产货 AI 集群从理念念酿成了实践。
同期跑两个 670 亿参数大模子是什么体验?
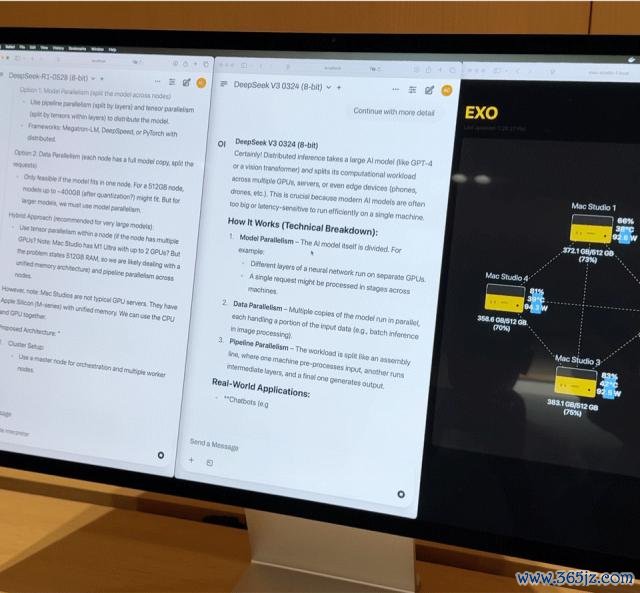
4 台顶配 M3 Ultra 的 Mac Studio 通过 Thunderbolt 5 串联后,账面数据极度惊东说念主:
128 核 CPU(32×4) 240 个 GPU 中枢(80×4) 2TB 长入内存(512GB×4) 总内存带宽擢升 3TB/s
这么的组合,真的是一台家用级别的微型超算。但硬件仅仅基础,委果发达效率的要道是 EXO Labs 设备的分袂式模子调遣平台 Exo。Exo 会证实内存与带宽现象将模子自动拆分,部署在最稳妥的节点上。
在现场,Exo 展示了以下中枢才能:
大模子加载:8-bit 量化后的 DeepSeek 完满载入需要 700GB 以上内存,单台 Mac Studio 无力承担。Exo 会将模子拆分部署到 2 台 Mac Studio 上完成加载。激活后,它的「打字速率」基本上擢升了东说念主的阅读速率。
并行推理:在开动 DeepSeek V3 的基础上,又加载了相似 670 亿参数的 DeepSeek R1。系统立行将 R1 分派到剩余的两台缔造上,终了两个大模子并行推理,支柱多用户同期发问。 文档出奇问答:拖入公司财报 PDF,模子在土产货完成学问镶嵌与问答,不依赖任何云霄资源,数据完好意思出奇可控。 轻量微调:若企业稀有千份里面贵寓,可通过 QLoRA + LoRA 手艺进行土产货微调。单台微调需耗时数日,而通过 Exo 的集群调遣才能,教师任务可线性加快,大幅裁汰时刻资本。 雄壮的资本互异
咱们在现场后台不雅察拓扑图发现:即使 4 台机器同期处于高负载现象,整套系统功耗永远狂妄在 400W 以内,开动真的无电扇杂音。
要在传统干事器决议中终了同等性能,至少需要部署 20 张 A100 显卡,干事器加集聚缔造资本超 200 万东说念主民币,功耗达数千瓦,还需零丁机房与制冷系统。
苹果芯片在 AI 波涛中有时找到了新定位

在算计打算 M 芯片之初,苹果更多是为节能、高效的个东说念主创作而生。但长入内存、高带宽 GPU、Thunderbolt 多旅途团员等特质,却在 AI 波涛中有时找到了新定位。
M3 Ultra Mac Studio 的起售价钱为 3999 好意思元,配备 96GB 长入内存,而 512GB 的顶配版块价钱如实腾贵。但从手艺角度来看,长入内存架构带来的上风是改革性的。
传统 GPU 即使是最高端的责任站卡,显存普通也惟有 96GB。而苹果的长入内存让 CPU 和 GPU 分享归拢块高带宽内存,幸免了数据在不同存储层级之间的频频搬运,这对大模子推理来说酷好要紧。
天然,EXO 这套决议也有彰着的定位互异。它不是为了与 H100 正面临抗,不是为了教师下一代 GPT,而是为了治理实质的支配问题:开动我方的模子,保护我方的数据,进行必要的微调优化。
要是说 H100 是金字塔顶的王者九游体育娱乐网,而 Mac Studio 正在成为中小团队手中的瑞士军刀。